ハイスループットRNA-sequencing(RNA-seq)は、その低コストと高いカバレッジにより、ここ10年で最も人気のある遺伝子発現プロファイリング技術になった。その結果、植物界からのRNA-seqライブラリの数は近年飛躍的に増加している。トウモロコシ、イネ、ダイズ、小麦、綿花などの主要作物について、2021年までに合計~45,000のライブラリを収集した。RNA-seqライブラリのビッグデータを最大限に活用するためには、統一された処理パイプラインによってすべての公開ライブラリを統合し、使いやすい検索可能なデータベースにキュレーションする取り組みが緊急に必要とされている。この課題に取り組むため、本著者らはウェブベースの包括的なプラットフォーム、Plant Public RNA-seq Database (PPRD, http://ipf.sustech.edu.cn/pub/plantrna/)を発表する。PPRDは、Gene Expression Omnibus (GEO), Sequence Read Archive (SRA), European Nucleotide Archive (ENA), and DNA Data Bank of Japan (DDBJ) データベースからのトウモロコシ (11,726), イネ (19,664), ダイズ (4,085), コットン (3,483) の多数の RNA-seq library から構成されている。
tutorial
http://ipf.sustech.edu.cn/pub/zmrna/tutorials.php
tutorialより
- PPRDは、標準化されたパイプラインを使用して、各ライブラリーの各遺伝子の発現量を算出しています。
- PPRDは、入力された遺伝子IDとライブラリIDを検索し、基本的な説明と発現量を返すことができます。
- PPRDは、検索結果のダウンロードと共有をサポートしています。
- PPRDは、IGV-webインターフェースも内蔵しています。
- PPRDは、他の生物種のホモログにアクセスし、その発現を確認することもできます。
http://ipf.sustech.edu.cn/pub/plantrna/にアクセスする。

Maizeをクリックした。
googleライクな検索を行うことができる。

キーワード、IDなど様々な方法で検索できる。

SRA accession IDで検索した。

Data Plotタブでは発現量(FPKM)のテーブルを閲覧できる。

およそ68000万遺伝子(行)あるが、とてもスムーズに動作する。
見出し行をクリックすると列ソートができる。見出し行のボックスからはフィルタリングもできる。

3つIDをカンマ区切りでタイプして検索した。

データテーブルタブでは検索したIDの列全て(ここでは3列)が確認できる。

右上のdownload ボタンからexcel形式の表をダウンロードできる。
Data plotタブ

IGV Onlineタブ

次はGene Symbolで検索する。

Data Tableでは、今度はサンプルが行となる。コムギは5816サンプルあるので5816行ある。

Data Plotでは、その遺伝子の組織ごと、品種ごとの発現量の分布が示される。

box plotをクリックすると拡大図が表示される。

Coexpression
neighborhoodで共発現している遺伝子のリスト
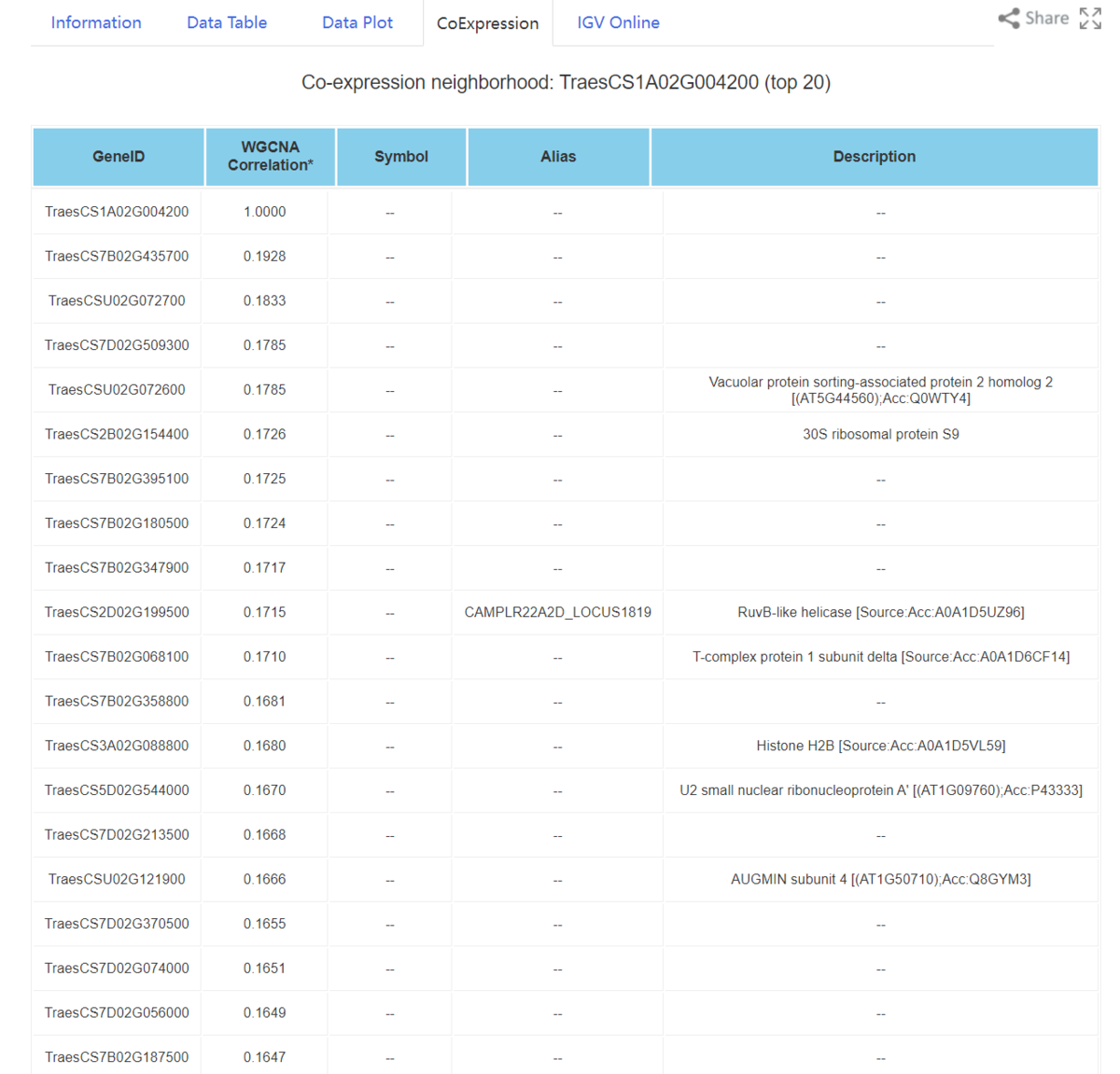
複数遺伝子の検索にも対応している。

より柔軟なキーワード検索も可能になっている。
アクセスしてみて下さい。
引用
PPRD: a comprehensive online database for expression analysis of ~45,000 plant public RNA-Seq libraries
Yiming Yu, Hong Zhang, Yanping Long, Yi Shu, Jixian Zhai
bioRxiv, Posted January 29, 2022
関連