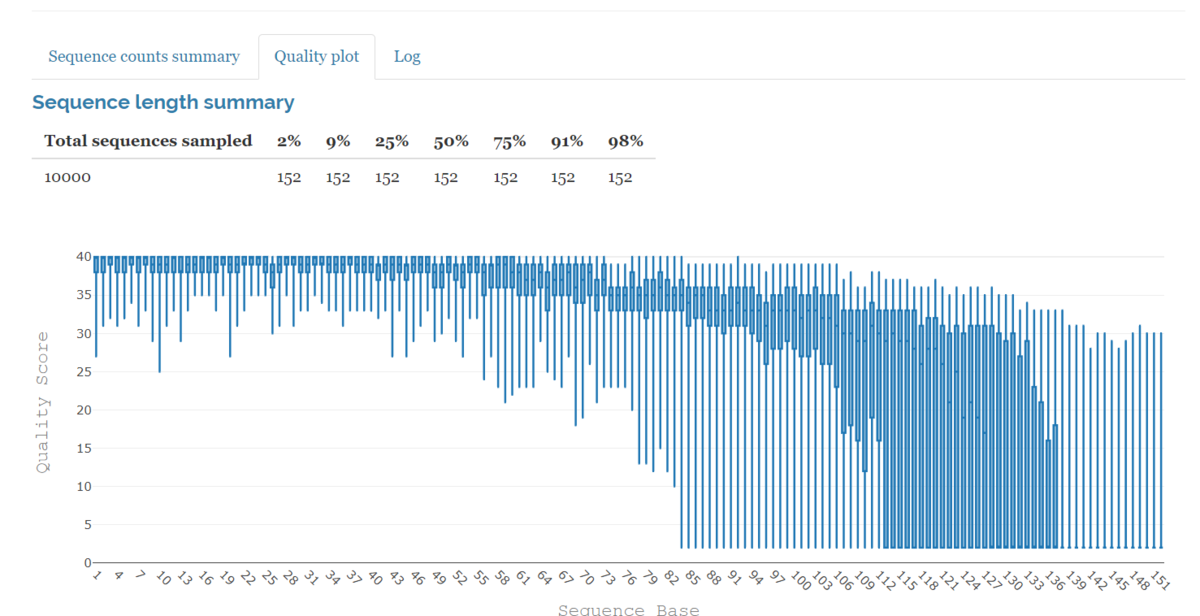
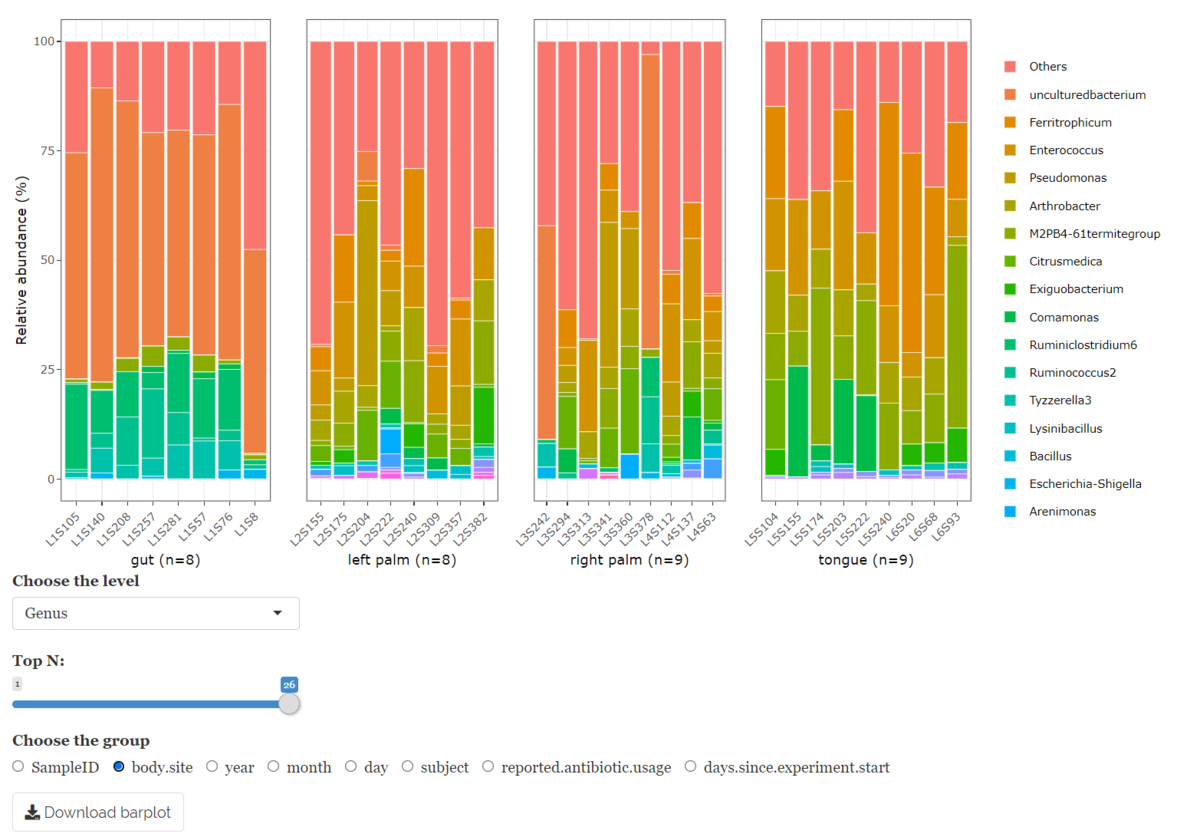
バイオインフォマティクスにおいて、祖先を共有する異なる生物種の遺伝子であるオルソログを予測することは重要な課題である。オルソログ予測ツールは、大量のデータを実行可能な時間内に解析するために、正確かつ高速に予測することが要求される。InParanoidはオルソログ解析のアルゴリズムとしてよく知られており、ベンチマークで良好な結果が得られているが、大規模なデータセットでは実行時間が長くなるという大きな制約がある。ここでは、InParanoidアルゴリズムのアップデート版として、相同性検索ステップにBLASTの代わりに高速なツールDIAMONDを使用できるようにしたものを紹介する。これにより、Quest for Orthologsベンチマークで同等の性能を得ながら、実行時間を94%削減することができた。ソースコードは(https://bitbucket.org/sonnhammergroup/inparanoid)で公開されている。
レポジトリより
InParanoid-DIAMONDは、異なるゲノムのタンパク質配列間の複雑なオーソログ関係を同定します。InParanoid-DIAMONDは、デフォルトの配列解析ツールであるBLASTに加え、DIAMONDを実装することにより、InParanoidの実行時間を最大93%短縮し、検出されたオルソログに対する信頼性はそのまま維持します。このパッケージは、DIAMONDスコアまたはBLASTスコアを用いてタンパク質の関連性を測定し、各グループに属する全てのパラログに対して信頼度を割り当てることができます。また、InParanoidはブートストラップ法を用いてオルソログの信頼度を計算することも可能です。
インストール
InParanoidは、プログラムの実行に必要なすべての依存関係を含むDockerコンテナとして提供している。公開されているdockerイメージを使用してテストした。inparanoidを実行するマシンでroot権限が得られない場合、Singularityを使ってDockerコンテナを実行することもできる(レポジトリ参照)。
#dockerhub(link)
docker pull sonnhammer/inparanoid
> docker run sonnhammer/inparanoid -help
###############################################################
InParanoid version 5.0
###############################################################
Accurate and fast ortholog detection with DIAMOND.
InParanoid-DIAMOND identifies complex orthologous relationships
between protein sequences from different genomes. The package is
capable of using either DIAMOND (default) or BLAST scores to
measure relatedness of proteins, and assigns confidence values
for all paralogs in each group.
RUN WITH DEFAULT SETTINGS AND TEST-FILES:
perl inparanoid.pl -input-dir ./testInput
OPTIONS:
-f1 Fasta file with protein sequences of species A
-f2 Fasta file with protein sequences of species B
-outgroup Fasta file with protein sequences of species C
to use as outgroup [Default: no outgroup]
-input-dir Directory containing fasta files for multiple
species. Will run all vs all. If this option
is used, leave -f1 and -f2 empty. Note that
InParanoid will run species pairs sequentially,
but Diamond will paralellize the sequence search
using all available threads.
-out-dir Specify a directory for the output files.
[Default: ./output]
-seq-tool Sequence similarity tool to use.
Options: Diamond, Blast [Default: Diamond]
-2pass Run 2-pass approach. Not suitable for Diamond,
recommended for Blast [Default: False]
-bootstrap Run bootstrapping to estimate confidence of
orthologs [Default: False]
-score-cutoff Set bitscore cutoff. Any match below this
is ignored [Default: 40]
-seq-cutoff Set sequence overlap cutoff. Match area should
cover at least this much of longer sequence.
Match area is the area from start of first
segment to end of last segment [Default: 0.5]
-seg-cutoff Set segment coverage cutoff. Matching
segments must cover this much of the
longer sequence [Default: 0.25]
-outgrp-cutoff Set outgroup bitscore cutoff. Outgroup sequence
hit must be this many bits stronger to reject
best-best hit between A and B [Default: 50]
-conf-cutoff Set confidence cutoff. Include in-paralogs
with this confidence or better [Default: 0.05]
-grp-cutoff Set group overlap cutoff. Merge groups if
ortholog in one group has more than this
confidence in other group [Default: 0.5]
-grey-zone Set grey-zone. This many bits signifies the
difference between 2 scores [Default: 0]
-sensitivity Set sensitivity mode for Diamond.
Options: mid-sensitive, sensitive, more-sensitive,
very-sensitive, ultra-sensitive.
[Default: very-sensitive]
-matrix Specify a matrix to use when running Blast.
Options: BLOSUM62, BLOSUM45, BLOSUM80, PAM30,
PAM70 [Default: BLOSUM62]
-out-stats Output statistics file [Default: False]
-out-table Output tab-delimited table of orthologs to file
[Default: False]
-out-sqltable Output sqltable file with orthologs [Default: True]
-out-html Output html file with groups of orthologs
[Default: False]
-out-allPairs Output allPairs file collecting all ortholog pairs
from all SQLtable files present in the output
directory. [Default: False]
-keep-seqfiles Use this option to keep the resulting sequence tool
files in the working directory. This will let you
run InParanoid without re-running the sequence
similarity tool. If false, these files will be moved
to the output dir when done [Default: False]
-diamond-path Explicitly state path to Diamond. Can be used if
Diamond is in a non-standard location, and not
in user PATH [DEFAULT: diamond]
-blast-path Explicitly state directory containing blastall and
formatdb. Can be used if Blast is in a non-
standard location, and not in user PATH.
-cores Use to specify the available cores. If DIAMOND is
used and this number is higher than twice the
-cores-diamond parameter, this number will be split
by -cores-diamond to run multiple instances of
InParanoid in paralell. If the number is lower, or
if only one proteome-pair is run, all cores will
be used to run DIAMOND. If BLAST is used, this
number will specify the number of paralell
InParanoid instances.
[Default: using all available cores]
-cores-diamond Use to specify the number of cores to use for each
DIAMOND run. To optimize performance, please make
sure that this number is dividable by the total
number of cores used [Default: 4]
-debug Activate debug mode [Default: False]
-notimes Hide execution times [Default: False]
-help/-h Show help
LICENSE:
Distributed under the GNU General Public License (GPLv3).
See file COPYING
実行方法
InParanoidをコンテナで実行するには、-vコマンドで入力と出力のディレクトリをコンテナにマウントする。InParanoidプログラムは、ディレクトリ内のすべてのファイルを自動的に実行する。ここでは、複数の生物種のファスタファイルが格納されているディレクトリを入力に指定する。
cd <path/to/your/input/files>/
mkdir outdir
docker run -v $PWD:/input -v $PWD/outdir:/output sonnhammer/inparanoid
-
-f1 Fasta file with protein sequences of species A
-
-f2 Fasta file with protein sequences of species B
-
-outgroup Fasta file with protein sequences of species C to use as outgroup [Default: no outgroup]
-
-input-dir Directory containing fasta files for multiple species. Will run all vs all. If this option is used, leave -f1 and -f2 empty. Note that InParanoid will run species pairs sequentially, but Diamond will paralellize the sequence search using all available threads.
-
-out-dir Specify a directory for the output files. [Default: ./output]
InParanoidでは、fasta形式のプロテオームファイルを2つ以上入力する必要がある。入力ファイルのフォーマットについては、testInput/以下にあるサンプルファイル、ECとSCを参照してください。2つのプロテオームでプログラムを実行する場合、-f1, -f2オプションでファイル名を指定する。2つ以上のプロテオームでプログラムを実行する場合は、-input-dirオプションで、複数のプロテオームをFasta形式で格納したディレクトリへのパスを指定する。これにより、ディレクトリ内の全てのペアのファイルに対して InParanoid が実行される。
出力について
InParnoidは、デフォルトでは、SQLtableファイルのみが出力し、コマンドラインオプション -out-stats, -out-html, -out-table を使用することで、statsファイル、htmlファイル、tableファイルを出力する。SQLtableはタブ区切りのテキストファイルで、検索で生成されたオルソログのグループを含んでいる。
引用
InParanoid-DIAMOND: faster orthology analysis with the InParanoid algorithm
Emma Persson, Erik L L Sonnhammer
Bioinformatics, Volume 38, Issue 10, 15 May 2022, Pages 2918–2919
関連